Idempotency and retries in API integration: reliability without duplicate transactions
A retry loop is not an exotic edge case. A client retries a POST because the TCP connection dropped just before the response came back. A message broker delivers the same event twice because a consumer restarted. A user clicks "Place order" twice because the first click looked like nothing happened. In production this happens daily, at every scale.
The question isn't whether retries occur — that one has long been answered, they do. The question is what happens on the receiving side. Does the receiving system rebuild the same transaction once more, or does it recognise the retry and quietly return the original answer? The difference between those two outcomes is exactly what idempotency is about.
What follows is a design that holds up in production: how to issue idempotency keys, where to store them, how to phrase error codes so retries are safe, and which anti-patterns cause you to charge the same payment three times.
What retries solve — and what they don't
Retries solve transient disruptions: a brief network blip, an overloaded downstream service, a database that's momentarily unreachable. The pattern is well-proven — a consumer retries with exponential backoff, and in the great majority of cases the second or third attempt succeeds.
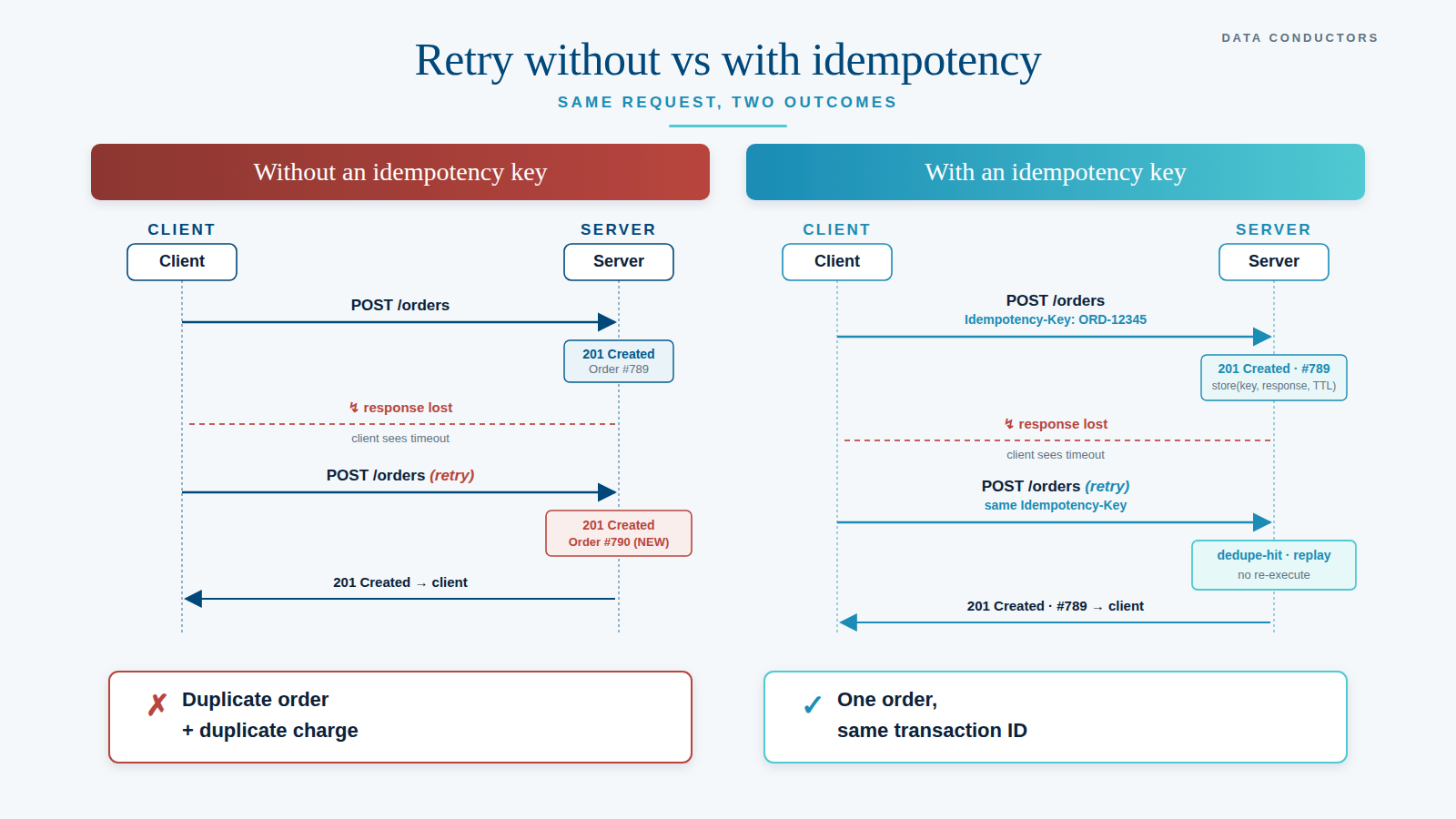
What retries don't solve — and actually make worse — is the scenario where the first attempt did succeed, but the response was lost in transit. The server processed the transaction; the client only saw a timeout. The client retries. The server, with no notion that this is a repeat, runs the same mutation again.
The result: a duplicate payment, a duplicate order, a duplicate customer record. The user gets two emails, accounting gets two entries, the CRM gets two profiles. And it wasn't even a bug — it was a correctly executed retry against an API that wasn't designed to receive that retry.
Idempotency: same operation, same end state
The definition is simple and strict: an operation is idempotent if repeated execution produces the same end state as a single execution. Sending the same POST three times must, at most, produce the side effects of one POST.
In practice this is rarely free. GET and DELETE are idempotent at the protocol level (RFC 9110), but POST, PATCH, and certain PUT variants are not automatically. For those methods the service owner has to design idempotency explicitly.
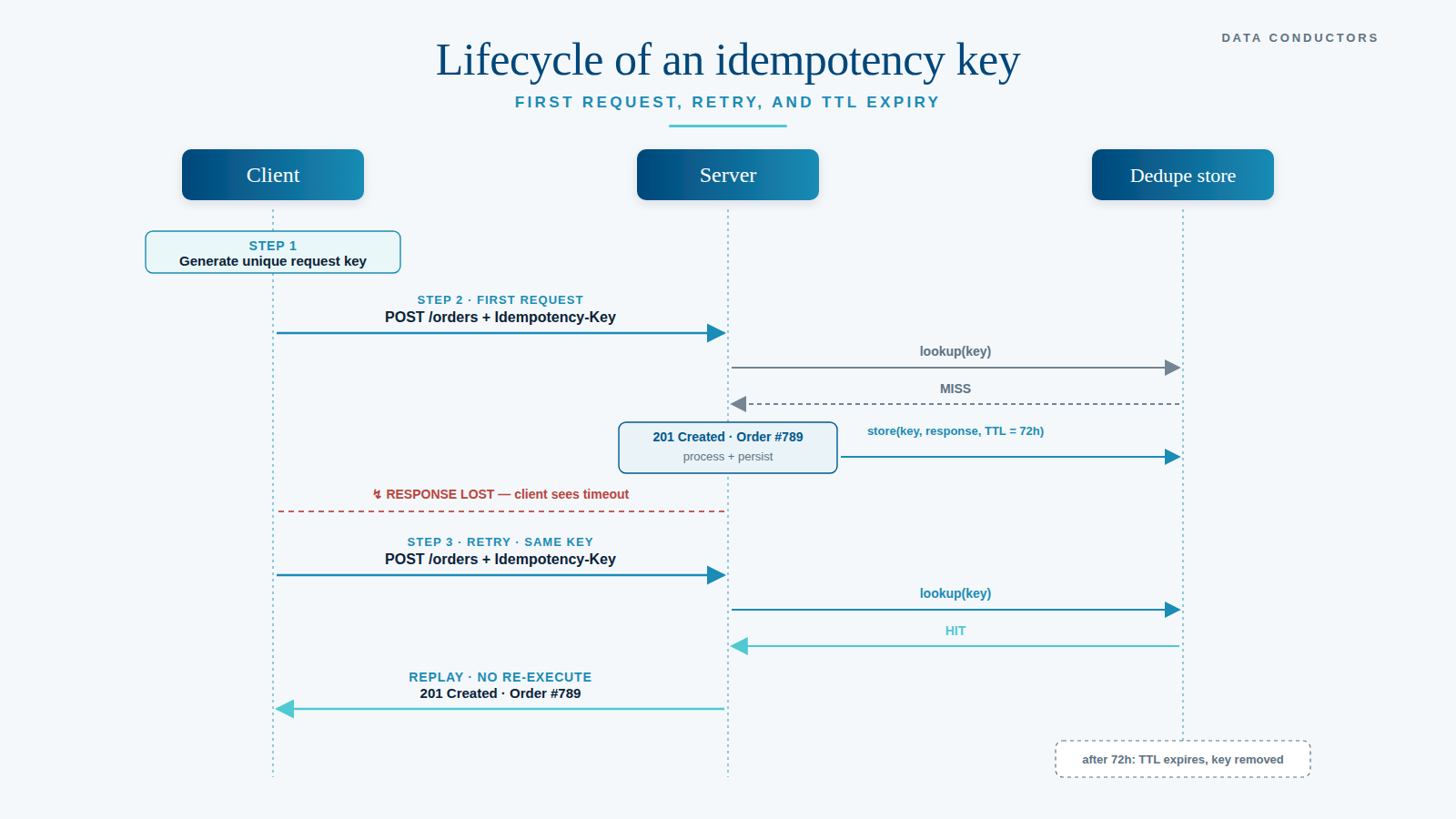
The standard pattern: the client generates a unique key per logical operation and sends it in a header — typically Idempotency-Key. The server uses that key to recognise duplicate requests, and on a repeat returns the original response without re-executing the operation.
The key — what it is and isn't
A good idempotency key has three properties. It is unique per logical operation (not per HTTP attempt — a retry reuses the key), independent of the payload (a hash of the body is not an idempotency key, that's a content fingerprint), and long enough to be collision-resistant (UUID v4 or v7 do the job fine).
The client is responsible for generation. A payment service generates one key per checkout attempt and reuses it for every retry within that same attempt. Only when the user starts a new attempt — deliberately, explicitly — is a fresh key generated.
The most common design slip: including the timestamp in the key. payment-{userId}-{timestamp} looks logical until you realise that every retry produces a new timestamp, so every retry is seen by the server as a new operation. Not idempotent. Confusing under analysis.
The dedupe store: more than just remembering a key
A server that supports idempotency needs a dedupe store: storage that, per (key, scope), remembers what happened. Three choices in that design are essential.
Store the full response, not just the key. On a retry, the server must return the same response the first request received — including status code, body, and relevant headers. Otherwise the client gets "201 Created" on retry-1 and possibly "404 Not Found" on retry-2, even though the resource exists. Persist the original response bytes.
Scope the key to the right boundary. An idempotency key is usually scoped per consumer and per endpoint. (consumerId, endpoint, key) is a common tuple. That prevents consumer A's key from accidentally matching consumer B's, and prevents the same key from accidentally addressing two different endpoints.
Pick the TTL pragmatically. For most transactional integrations, 24 to 72 hours is ample — longer than any realistic retry window, shorter than would let the store grow unnecessarily. For financial transactions, organisations often pick 7 days. The thing to avoid above all: a retry that arrives after the TTL has expired and is therefore processed as a new operation.
For implementation: Redis with expiry for hot-path performance, a DB table for durability if a crash mustn't wipe the Redis state. Both, in heavier systems.
Error codes that make a difference
The HTTP status codes you return determine how intelligent the client can be about retries. Three categories deserve sharp attention.
5xx: try again later. 500, 502, 503, 504 — the server has a problem that may be transient. The client may — and should — retry with backoff. This is exactly what idempotency protects against.
4xx: stop retrying. 400 (malformed), 401 (unauthorised), 403 (forbidden), 422 (unprocessable). A retry will produce the same result. The client should surface the error to the user or push it into a dead-letter queue — not retry.
409 Conflict on key reuse with a different payload. This is the subtle one: same idempotency key, different body. Two possibilities: either the client accidentally used the same key for two operations (programming error), or there's a hash collision in a too-short key. In both cases, "silently process the first payload" is dangerous. Return 409, log it, and let the client decide.
A status code worth using deliberately: 202 Accepted for async processing where the final status arrives later via a GET status endpoint or webhook. Even in an asynchronous model, idempotency on the accept step still matters — it prevents the same job from landing twice in the queue.
Practice: four patterns where this becomes visible
Payment APIs. Every serious payment provider mandates an idempotency key. Stripe, Adyen, Mollie — they all require it for charge and capture endpoints. A retry with the same key returns the same transaction ID, not a fresh charge. First subject of any integration review: does the PSP client correctly forward the key on every retry?
Webhook delivery. A webhook provider promises "at-least-once delivery" — which in practice means "sometimes more often". The consumer must dedupe based on the event ID the provider includes. Same event ID? Ignore. This is webhook idempotency from the consumer side, and it's non-negotiable for production.
Order placement. A user clicks "Place order". The client generates an idempotency key as soon as the checkout flow starts, and reuses it for every retry within the same session. Three clicks → one order. After that the key is consumed and a fresh checkout becomes a fresh order.
Contact form submissions. Small in scope, same rules. If a form submit times out, the client retries. Without idempotency, two submissions land in the inbox. With an idempotency key (generated by the client at the moment of first submit), the second is ignored or returns the same "received" response.
Anti-patterns to push back on, hard
The server generates the key. Then no idempotency is possible — a retry gets a new key. The client must generate it, or at minimum forward it.
Body hash as the key. Tempting, because "same content → same key, magically idempotent". But two users who happen to send the same body (more likely than you'd think with standardised payloads) collide. And a retry where the client adds a field — correlation ID, attempt count — breaks the hash.
No response replay. Server only remembers "this key was seen" and returns a fresh answer on retry. With a 201 Created → 200 OK retry, the effect is confusing; with 201 → 404 (because the resource was cleaned up elsewhere), it's broken. Persist the original response.
TTL shorter than the retry window. A client does exponential backoff up to 24 hours. The server TTL is 1 hour. Retry 21 arriving at hour 22 is processed as a new operation. Two transactions.
Idempotency only on the happy path. If the first request fails halfway (database crash after partial commit, external call succeeded but local write failed), the retry must know that an earlier attempt left an incomplete state behind. Idempotency on write without transactional integrity on the server is half-finished work.
Operational discipline around replays
Idempotency is not a configuration question — it's an operational discipline. Three things need to be visible in production.
Metrics on duplicate rate. How many requests per endpoint are duplicate retries? A low rate (single percentage points) is normal. A sudden high rate points to a client retrying too aggressively, or to a network issue worth investigating.
Logging on key collisions. Every 409 on key reuse with a different payload is a signal: either a client bug, or a hash weakness. Investigate these before they become silent corruption.
Replay safety in the tests. Every handler that performs mutations should have a test that calls it twice with the same key and verifies that the result — data in DB, side effects, response — is identical to a single call. Not "approximately the same", but bit-identical where the behaviour is observable.
A quick self-test
Five questions about your current integration landscape:
- Which endpoints accept an
Idempotency-Keyheader, and is that documented in the contract? - What is the TTL of your dedupe store, and is it longer than the maximum retry window of your clients?
- On a duplicate request, is the original response returned bytewise, or is a fresh response generated?
- What happens with the same key and a different payload — 409, or silent execution of the first body?
- Does every webhook consumer have a dedupe layer on event ID, or does it trust the provider not to duplicate?
An honest "no" or "we don't know" on any of these isn't failure — it's the starting point for a review.
In closing
Idempotency sounds like an implementation detail to add later. In practice it's a design choice that has to be made on day one, because adding it afterwards is almost always more expensive — and in most systems requires breaking retroactive assumptions about what happens on a retry.
Good integrations fail gracefully, and retries are the difficult half of graceful. An API that ignores idempotency can look impeccable in demos and in tests, and still produce duplicate transactions in production the moment the network hiccups once.
Is your organisation wrestling with duplicate transactions or uncertainty about the retry-safety of its API integrations? A short integration audit surfaces the risks and shows which endpoints deserve attention first.